-
-
Published
Linked with GitHub
# Constant Time Reward Distribution with Changing Stake Sizes and Deferred Reward
## Introduction
The paper of [Scalable Reward Distribution with Changing Stake Sizes](https://solmaz.io/2019/02/24/scalable-reward-changing/) defines a method to build a pull-based reward system with constant time computation and with the capability of changing the already staked amount. Although these two features are desirable, a participant can still stake just at the moment of the reward distribution, withdrawing the stake just later. This creates an unfair situation where these participants are getting the same reward as other participants that have staked for the complete period duration.
In this paper, we propose an extension to this method to force a fair reward, while keeping the core features. In our solution, the participants are forced to keep the stake during some period if they want to get the reward. The participants can withdraw their stake at any moment, but if they do, they are not rewarded with the last distributed reward. This incentivizes participants to deposit stake during a complete period, and avoid malicious participants to stake only a small part of the time, behavior that breaks the main purpose of a reward system.
## Methodology
We call *Deferred Reward* to the process of evaluating the reward for a participant one distribution later, given them the reward only if the amount was staked from the previous distribution.
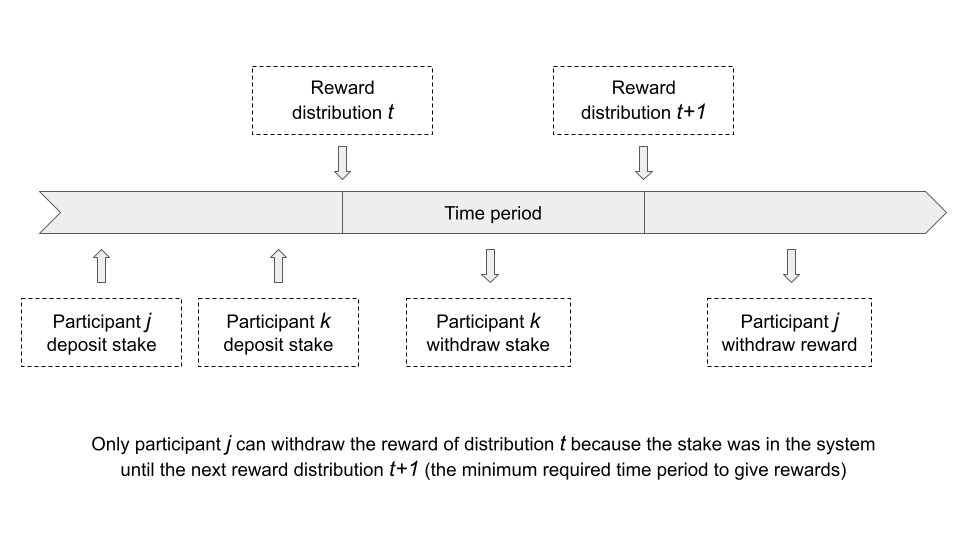
This feature can be built in three incremental phases: delayed reward, reverted reward and reinjected reward.
*The reader is supposed to understand the equations of the cited paper in order to follow this explanation. This document will refer to them in several occasions.*
### A. Delayed reward
Our proposal starts by delaying the reward to the next distribution in order to simulate an interval where the rewards are not yet available.
The delayed reward, a participant $j$ would receive for a distribution $t$ is:
$$
delayed\_reward_{j,t} = reward_{j,t-1} = stake_{j,t-1} \frac{reward_{t-1}}{T_{t-1}}
$$
Then, the total delayed reward can be calculated as:
$$
total\_delayed\_reward_{j,t} = \sum_{t} delayed\_reward_{j,t} = \sum_{t=1}^t stake_{j,t-1} \frac{reward_{t-1}}{T_{t-1}}
$$
We can make explicit the difference in order to use the last $t$ in all components:
$$
total\_delayed\_reward_{j,t} = \sum_{t} stake_{j,t} \frac{reward_t}{T_t} - stake_{j,t} \frac{reward_t}{T_t}
$$
And then, be able to substitute the left-hand side of the subtraction with the $total\_reward$ defined in the paper:
$$
total\_delayed\_reward_{j,t} = total\_reward_{j,t} - stake_{j,t} \frac{reward_t}{T_t}
$$
Reusing the mathematical development of $total\_reward_{j,t}$ we have the following equation:
$$
total\_delayed\_reward_{j,t} = stake_{j,t} \times reward\_per\_token_t - reward\_tally_{j,t} - stake_{j,t} \frac{reward_t}{T_t}
$$
This works when the $stake_{j,t}$ represents the exact stake that has been rewarded. That is, the system distributes the reward, and then, without altering the stake amount, the participant $j$ withdraws the reward.
Looking deeply to the $total\_reward_{j,t}$ definition, we can notice the following equality:
$$
total\_reward_{j,t} = stake_{j,t} \times reward\_per\_token_t - reward\_tally_{j,t} = \\ = stake_{j,t+1} \times reward\_per\_token_{t} - reward\_tally_{j,t+1}
$$
Which means that it also supports cases where the stake given has not been rewarded yet: $stake_{j, t+1}$. This is, when the participant alters the stake after the system distributes the reward. Because this form of the equation encompasses more possibilities, we can rewrite the total delayed rewards using it:
$$
total\_delayed\_reward_{j,t} = stake_{j,t+1} \times reward\_per\_token_t - reward\_tally_{j,t+1} - stake_{j,t} \frac{reward_t}{T_t}
$$
### B. Reverted reward
With the previous definition, we have delayed the rewards to one more distribution. Nevertheless, this is not enough, a participant can withdraw stake after one distribution and will be rewarded anyway, although their stake has not been in the system until the second distribution.
To protect from that, we need to revert the reward associated with the stake amount the participant wants to withdraw. To achieve this revert, we need to cheat the system to believe the withdrawal would have been done before the last distribution.
In order to resolve this, we need to know that we have two classes of stake in the participant account: A rewarded stake and an unrewarded stake.
The $unrewarded\_stake$ given by $stake_{j,t+1} - stake_{j,t}$, can be withdrawn as usual, using the reward per token of distribution $t$ to compute the correct reward tally. We call the amount subtracted to this stake: $unrewarded\_amount$.
The $rewared\_stake$ given by $stake_{j,t}$, needs to use the previous reward per token of the previous distribution $t-1$ to cheat the account as if the withdrawal would have been done before the last distribution. We call the amount subtracted to this stake: $rewarded\_amount$.
As we can see, the substracted amount for a withdrawal $n$ is splitted into two:
$$
amount_n = unrewarded\_amount_n + rewarded\_amount_n
$$
Now we can represent the change in reward tally after the withdrawal as two differents withdrawals:
$$
\Delta reward\_tally_{n,t} = -unrewarded\_amount_n * reward\_per\_token_{t} - \\ - rewarded\_amount_n * reward\_per\_token_{t-1}
$$
And keeping in mind the following relation:
$$
\frac{reward_t}{T_t} = reward\_per\_token_{t} - reward\_per\_token_{t-1}
$$
We can reformulate using the same $t$ for all components.
$$
\Delta reward\_tally_{n,t} = -amount_n * reward\_per\_token_{t} + rewarded\_amount_n \times \frac{reward_t}{T_t}
$$
To avoid tracking the $reward\_per\_token_{t-1}$ value only for the case of the withdrawal.
### C. Reinjected reward
Dividing the withdrawal stake process into two different stages ensures a correct reward tally for the accounts, but we introduce an error in the system. The system assumes that all the given reward ends up in the accounts, but we are withdrawing rewarded stake that no longer is rewarded, so that reward is lost.
To solve this, we need to reinject the lost reward into the system. The lost reward introduced by a withdrawal stake action is:
$$
lost\_reward_{n,t} = rewarded\_amount_n \times \frac{reward_t}{T_t}
$$
That corresponds to the right-hand side of the sum in the $\Delta reward\_tally_{n,t}$ calculation.
This lost reward originated by all different withdraws and participants is reinjected as a reward in the next distribution:
$$
reward\_per\_token_{t} = \sum_{t} \frac{reward_{t} + \sum_{n} lost\_reward_{n,t-1}}{T_{t}}
$$
This way, we ensure there is always the expected reward in the system.
## Implementation
The following basic Python implementation represents how to implement the *Deferred Reward* solution for the same methods found in the paper.
```python
class PullBasedDistribution:
"Constant Time Reward Distribution with Changing Stake Sizes and Deferred Reward"
def __init__(self):
self.total_stake = 0
self.reward_per_token = 0
self.last_rate = 0
self.lost_reward = 0
self.current_distribution_id = 0
self.stake = {0x1: 0, 0x2: 0}
self.reward_tally = {0x1: 0, 0x2: 0}
self.rewarded_stake = {0x1: 0, 0x2: 0}
self.distribution_id = {0x1: 0, 0x2: 0}
def __update_rewarded_stake(self, address):
"Ensure the `rewarded_stake` contains the last rewarded stake"
if self.distribution_id[address] != self.current_distribution_id:
self.distribution_id[address] = self.current_distribution_id
self.rewarded_stake[address] = self.stake[address]
def distribute(self, reward):
"Distribute `reward` proportionally to active stakes"
if self.total_stake == 0:
raise Exception("Cannot distribute to staking pool with 0 stake")
self.last_rate = (reward + self.lost_reward) / self.total_stake
self.reward_per_token += self.last_rate
self.lost_reward = 0
self.current_distribution_id += 1;
def deposit_stake(self, address, amount):
"Increase the stake of `address` by `amount`"
self.__update_rewarded_stake(address)
self.stake[address] += amount
self.reward_tally[address] += self.reward_per_token * amount
self.total_stake += amount
def withdraw_stake(self, address, amount):
"Decrease the stake of `address` by `amount`"
if amount > self.stake[address]:
raise Exception("Requested amount greater than staked amount")
self.__update_rewarded_stake(address)
unrewarded_stake = max(self.stake[address] - self.rewarded_stake[address], 0)
unrewarded_amount = min(amount, unrewarded_stake)
rewarded_amount = amount - unrewarded_amount
lost_reward = rewarded_amount * self.last_rate
self.stake[address] -= amount
self.reward_tally[address] -= self.reward_per_token * amount - lost_reward
self.total_stake -= amount
self.rewarded_stake[address] -= rewarded_amount
self.lost_reward += lost_reward
def compute_reward(self, address):
"Compute reward of `address`. Inmutable"
previous_stake = self.rewarded_stake[address]
if self.distribution_id[address] != self.current_distribution_id:
previous_stake = self.stake[address]
return (self.stake[address] * self.reward_per_token
- self.reward_tally[address]
- previous_stake * self.last_rate)
def withdraw_reward(self, address):
"Withdraw rewards of `address`"
reward = self.compute_reward(address)
self.reward_tally[address] += reward
return reward
# Example
addr1 = 0x1
addr2 = 0x2
contract = PullBasedDistribution()
contract.deposit_stake(addr1, 100)
contract.deposit_stake(addr2, 50)
contract.distribute(10)
contract.withdraw_stake(addr1, 100)
contract.deposit_stake(addr1, 50)
contract.distribute(10)
# Expected to not be rewarded because the participant withdrawed stake before the second distribution (0)
print(contract.withdraw_reward(addr1))
# Expected to be rewarded with the third part of the reward (3.3)
print(contract.withdraw_reward(addr2))
```
## Conclusion
The original paper gives two important features for a reward system: constant time computation and stake size changes. With two more arithmetic values stored by account we are able to add a new feature to it without losing capabilities: give the reward only if the participant holds the stake in the system for a period. This feature is important to incentivize participants to stake during the time and to avoid malicious behaviors of participants that stake only during the moment the reward is given in the system.
## Appendices
- [Deferred mechanism proposal](https://docs.google.com/presentation/d/1EwEcsXVc5HLyULQehz1L-0XMOf7KGuvQWAYVgKcS2Qk/edit?pli=1#slide=id.g1613d09df7c_0_350): A more programatic explanation of this method.
- [Substrate pallet implementation](https://github.com/centrifuge/centrifuge-chain/tree/main/pallets/rewards): Rust implementation used in centrifuge.io
## References
- [Scalable Reward Distribution](http://batog.info/papers/scalable-reward-distribution.pdf)
- [Scalable Reward Distribution with Changing Stake Sizes](https://solmaz.io/2019/02/24/scalable-reward-changing/)